Kafka is a useful publish and subscribe (Pub-Sub) management platform that is widely used in Big Data. It is a distributed stream platform that is known for its fault-tolerant storage system.
Most of us have gone through the terms Apache Kafka and Confluent Kafka and often wondered, are they any different to each other?
Well, we will be discussing how Confluent Kafka and Apache Kafka are different and what sets them apart. We will be using some key parameters that will help us understand the difference with ease.
Confluent Kafka vs. Apache Kafka: Key Differentiating Factors
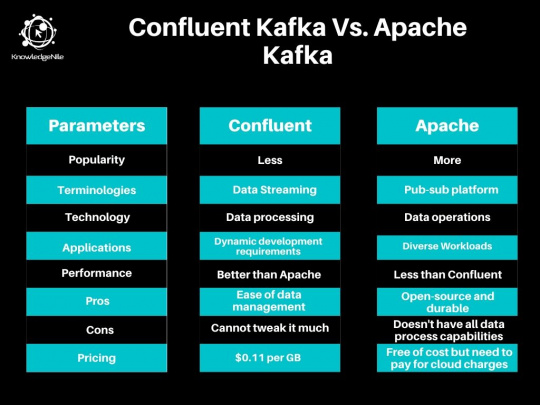
Confluent Kafka vs. Apache Kafka: Popularity
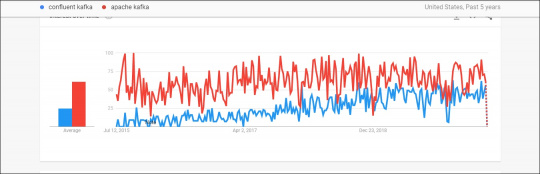
From the above-mentioned graph, we can say that Apache Kafka is a more popular tool than Confluent Kafka over the last five years.
But there were a few periods when both had an equal amount of traction and for some periods Confluent Kafka was more popular.
Confluent Kafka vs. Apache Kafka: Terminologies
Confluent Kafka is mainly a data streaming platform consisting of most of the Kafka features and a few other things.
Its main objective is not limited to provide a pub-sub platform only but also to provide data storage and processing capabilities.
While on the other hand, Apache Kafka is a pub-sub platform that helps companies transform their data co-relation practices.
Its main objective is to provide a streaming platform that can allow the companies to send push notifications to its users based on the initiated actions.
Confluent Kafka vs. Apache Kafka: Technology Type
While both platforms fall under big data technologies, they are classified into different categories. Confluent Kafka falls under the data processing category in the big data.
On the other hand, Apache Kafka falls under the data operations category as it is a message queuing system.
Also Read: What's the Difference Between Apache Kafka and JMS?
Confluent Kafka vs. Apache Kafka: Performance
Confluent Kafka performs really well, and even under the higher workloads, its performance is unwavering.
On the other hand, though Apache Kafka performs well, it still lags behind Confluent Kafka’s performance.
Confluent Kafka vs. Apache Kafka: Pros and Cons
Confluent Kafka Pros
- It has almost all the attributes of Kafka and some extra attributes as well.
- It streamlines the admin operations procedures with much ease.
- It takes the burden of worrying about data relaying, off the data managers.
Confluent Kaka Cons
- Confluent Kafka is created by using Apache Kafka, and hence the scope of tweaking it further is limited.
- Confluent Kafka’s fault-tolerant capabilities may be questioned in some cases.
Apache Kafka Pros
- Apache Kafka is an open-source platform.
- It allows you to have the flexibility and features to tweak the code as per your requirements.
- It is known for its fault tolerance and durability.
- It is easily accessible and gives you real-time feedback.
Apache Kafka Cons
- It is only a pub-sub platform and doesn’t have the entire data processing and data operations tools.
- In some cases, if the workload goes too high, it tends to work an awry manner.
- You cannot use the point-to-point and request/reply messages in Apache Kafka.
Confluent Kafka vs. Apache Kafka: Pricing
The pricing model of Confluent Kafka is based on cloud usage, and typically it costs you around $0.11 per GB. The usage calculated based on the data stored on the Confluent Cloud.
Apache Kafka is an open-source platform that you can use for free, but you need to store the data on your cloud/on-premise platforms.
Tabular Comparison of Apache Kafka and Confluent Kafka
Key Takeaways
Confluent Kafka has far more capabilities than Apache Kafka, but you need to pay to use Confluent Kafka.
But, Apache Kafka is free of cost, and you can make the tweaks as per your requirements on the platforms too.



0 Comments